
# 神经网络基本原理
解决的问题:特征提取(哪些特征比较合适)
应用:检测、识别
# 前向传播
前向传播:得出损失值

(其中 为输入数据, 为权重参数, 为损失值)
# 得分函数
线性函数:从输入 -> 输出的映射
其结果表示输入数据对于每个分类的得分。
数学表示:
其中 为图像, 为权重参数, 为偏置参数。
通常 对结果起决定作用, 对结果起微调作用;
假设图片为 ,共有 10 个分类,
则 为 , 为 , 为, 最终结果为 ;
表示该图像分别对这 10 个分类的得分。
深度学习其实就是在寻找最优的
# 损失函数
衡量 分类的结果 和 真实情况 之间的差距。
损失函数 = 数据损失 + 正则化惩罚项
数据损失 (Data Loss):数据 造成的损失
例如 ,
其中 表示真实的分类结果

则
正则化惩罚项:权重参数 造成的损失(与数据无关)
,
其中 为惩罚系数,越大表示越不希望发生过拟合
Softmax 分类器
(分类问题,因为要的是概率值)
由 得分值 获得 概率值,再将其转化为 损失值
- 放大 得分值之间的 差异 :()
- 归一化: (,)
- 计算损失值: ()
# 反向传播
反向传播:优化模型(找到使 损失值 最小的 )
梯度下降算法:判断损失值是否达到最小,否则进行优化:
反向传播遵循链式法则:梯度是从后往前、逐层传播的
沿着输出层的 输出结果 的计算顺序的 倒序 进行反向传播
=> 比如 ,则反向传播时 先计算 的梯度。整个过程可以划分出多个门单元:
- 正向传播中,下一门单元的输入数据 为 上一个门单元的输出数据
- 反向传播从最后一个门单元开始,
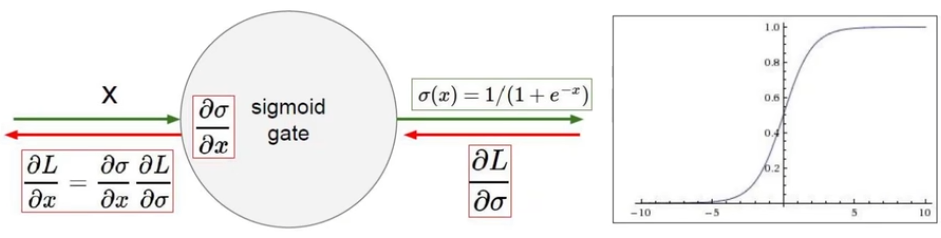
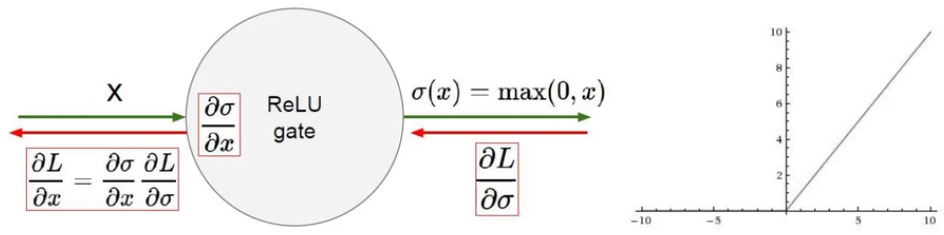
如下图,红框中的部分就是一个门单元;
箭头上方的绿色部分为前向传播的内容,表示当前门单元的输出(也是下一个门单元的输入);
箭头下方的红色部分为反向传播的内容,表示上一个门单元计算得到的梯度。

门单元:(一种操作)
- 加法门单元:
对于 ,因为 对 和 求偏导的值都是 1,所以 和 向后传播的梯度不变。
(后面传来的梯度会均匀地分给 和 )- 乘法门单元:
对于 ,因为 对 求偏导为 ,对 求偏导为 ,所以
(互换)- MAX 门单元:
后面传来的梯度 只会 传递给输入值 最大的 那一项,其余小的项的梯度均为 0。
# 整体架构

层次结构:神经网络是分层的。每一层在前一层的基础上 对数据进行变换。
神经元:数据的特征数量。比如输入层有 3 个神经元,其实表示输入数据为 的矩阵,即存在 3 个特征。
(隐藏层 1 中有 4 个特征,隐藏层 2 同理)全连接:对于中间的每一层的神经元,都与前一层每个神经元连接起来。
(连接:权重参数矩阵,如上图 为 ,,)非线性:与进入下一层之前,要先将数据带入一个非线性函数(激活函数)。
(并不是直接进行矩阵乘法得到下一层)
神经元个数越多,得到的拟合程度越大,在训练集上得到的效果越好,但运行速度也越慢,过拟合风险也越大
# 激活函数
在进入下一层之前,需要将结果带入 激活函数(activation function)

常用的激活函数:
- Sigmoid
![image-20240204104322221]()
存在问题:(因此不怎么使用)- 梯度消失:因为某一步操作导致梯度为 0
(因为梯度下降算法是乘法操作,如果某一步梯度为 0,则后续都不会进行更新)。
Sigmoid 函数最左和最右侧的点,梯度约等于 0。
- 梯度消失:因为某一步操作导致梯度为 0
- Relu
![image-20240204105235840]()
最常用的激活函数 - Tanh
- ...
# 数据预处理
- 中心化(获得 zero-centered data) => 每个数据减去均值
- 维度放缩(获得 normalized data) => 每个数据除以标准差

# 参数初始化
(初始化 权重参数矩阵)
通常使用 随机策略 进行参数初始化:
乘以 0.01 的原因:
我们希望 中的数据 浮动较小(浮动较大的模型更容易导致过拟合)
# 过拟合解决方法
- 正则化惩罚项(损失函数中加入 项)
- DROP-OUT(七伤拳)
- ...
DROP-OUT:
在 每一次 的神经网络的训练过程中,对每一层都随机地杀死一些神经元
(每次 不使用 的神经元都是随机的)
